Here’s another puzzle that had me occupied all of my bike ride home yesterday:
While stopped at an intersection, I noticed how the windows on the building across the street allowed me to see oncoming traffic from the side from farther away than I had turned my head. And so I wondered, what relation and how much of a reduction in neck strain does such a situation promote?

Clearly you need to turn your head only b degrees instead of a degrees, but that relationship can be anywhere from a negligible difference when the target is right against the mirror to a near complete reduction if the mirror was at infinity. What’s the actual relationship though?

The target is at some x and y position away from us the viewer, and in the case of a building where the reflection is always ideally positioned, it only matters the y’ distance of the building from the target (the image will be the same distance behind the mirror).
With all of three of these values, we can find the angle of the triangles formed in the diagram by arctan(y/x) and arctan((y+2y’)/x).
The angle I must turn to look at a car then is (90º – arctan(y/x)), while I only need to turn (90º – arctan((y+2y’)/x)).
Wolfram alpha can help us with the rest of the work here in visualizing this relationship, and we can choose to look at all three as variables or arbitrarily set certain one’s as constants.
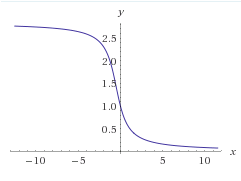
For example, if we are interested in how the ratio of the reduction behaves as a function of the distance of the mirror, see the following graph. The ratio of the image in the mirror angle to the object angle is y and the distance of the mirror from the object is x in this case. (as expected, mirror farther away means you have to turn your head less)
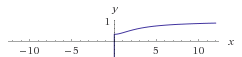
Or, if we are interested in how the ratio of the reduction behaves as a function of the x position of the object (the farther away it is, the closer the angle is between the mirror image and it):
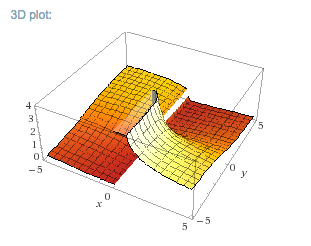
Or we can vary both the position of the object and the mirror at the same time (reflected in the top right quadrant of the below graph since both values can only be positive):
ADDITIONAL:
By the way, if you were wondering about the ideal positioning of a mirror to see an object at your side, the relationship is governed by (y+y’)/(x-x’) = y’ / x’ where x and y are the position of the desired target object to your side and x’ and y’ are the position of the mirror relative to that object.

x’ and y’ have an expected asymptotic relationship where they start right on top of the target to halfway between you and the target in x while infinitely far away in y. Per Wolfram Alpha below (setting y=1 and x=2).